ping Datenbank
Pingplot war als Vorbereitung für ein etwas größeres Projekt gedacht, für das ich eine Datenbank einsetzen möchte. Also sollte ich erst mal lernen, wie man mit Datenbanken arbeitet.
Tatsächlich habe ich am Ende etwas mehr gelernt als gedacht und ein bisschen älteres Wissen aufgefrischt.
Grundidee
Daten, die laufend generiert werden sollen gesammelt und visualisiert werden. Zum Üben nehme ich den Ping zu einer Website. Der eignet sich weil es ein beständiger Strom von nicht zufälligen, aber auch nicht voraussagbaren Datenpunkten ist.
Es wird 4 zentrale Programme in unserem Setup geben:
- Die Steuerzentrale
- Die Datenquelle
- Die Datenbank
- Die Datenaufbereitung
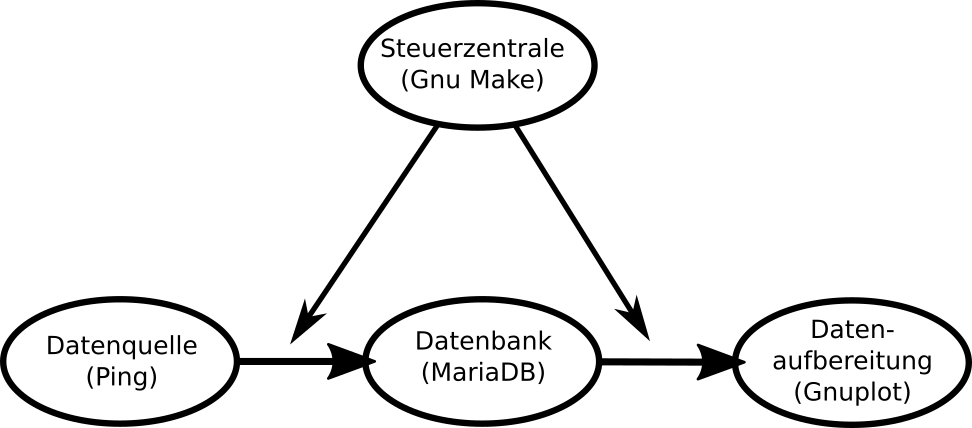
Mir ist wichtig, das am Ende alles auf Knopfdruck funktioniert. Der Befehl, einen Plot zu erstellen ist nur ein Befehl sein und es ist keine weiteres Eingreifen meinerseits notwendig, erst recht kein hin- und herkopieren von Daten. Dieses Prinzip hat sich bei meiner Bachelorarbeit extrem gut bewährt - irgendwann drückt man nur noch auf den Knopf und hat etwas später 50 Graphen und Diagramme, die man analysieren kann.
Die Steuerzentrale - Gnu Make
Als ich zum ersten mal ein Makefile benutzt habe war ich wirklich begeistert von der Idee: Wenn man in einem Directory ohnehin immer wieder das gleiche macht, kann man das auch automatisieren. Und tatsächlich habe ich beim Programmieren immer ein Terminal laufen, in das ich permanent die selben Sachen eingebe:
- compilieren
- testcase mit den einen Parametern
- testcase mit den anderen Parametern
- Zwischenergebnisse aufräumen, um sie neu zu erstellen
- git
- temporäre Dateien aufräumen– Ups, da war was Wichtiges dabei :(
Stattdessen schreibt man ein Makefile, indem das alles vorformuliert ist und gibt dann nur noch Befehle wie:
make compile
oder
make plot
Dank tab-completion geht das schneller und man vertippt sich nicht ausversehen. Ich finde es ja allgemein ganz gut, wenn ein Programm möglichst viel über sich selbst weiß und sich selbst quasi selbst organisiert (Solange klar ist, das ich noch der Chef bin - die Apple-Lösung mit diesen Mediathekformat, in das man nicht reinschauen kann).
Die Syntax von Makefiles ist erstmal sehr einfach. Man schreibt das target auf, einen Doppelpunkt dahinter - und danach eingerückt die Befehle, die ausgeführt werden sollen wenn das target aufgerufen wird.
plot:
gnuplot graph.plot
feh --reload 1 ping.png &
Mehr muss man erstmal nicht wissen.
Die Datenquelle - ein kurzes Shell-Skript
Um den Ping zu einer Website herauszufinden, reicht ein einfaches
$ ping www.schauderbasis.de
PING www.schauderbasis.de (5.45.107.67) 56(84) bytes of data.
64 bytes from v22013121188416155.yourvserver.net (5.45.107.67): icmp_seq=1 ttl=61 time=29.9 ms
64 bytes from v22013121188416155.yourvserver.net (5.45.107.67): icmp_seq=2 ttl=61 time=37.2 ms
64 bytes from v22013121188416155.yourvserver.net (5.45.107.67): icmp_seq=3 ttl=61 time=28.2 ms
...
Uns interessieren die Werte zwischen time= und ms. Um die
herauszubekommen hat für mich folgendes funktioniert:
- Nur noch ein Wert stat unendlich viele:
$ ping -c 1 www.schauderbasis.de
PING www.schauderbasis.de (5.45.107.67) 56(84) bytes of data.
64 bytes from v22013121188416155.yourvserver.net (5.45.107.67): icmp_seq=1 ttl=61 time=29.8 ms
--- www.schauderbasis.de ping statistics ---
1 packets transmitted, 1 received, 0% packet loss, time 0ms
rtt min/avg/max/mdev = 29.865/29.865/29.865/0.000 ms
- Nur noch die zweite Zeile, wo die wichtige Information drin steht:
$ ping -c 1 www.schauderbasis.de | sed -n 2p
64 bytes from v22013121188416155.yourvserver.net (5.45.107.67): icmp_seq=1 ttl=61 time=28.9 ms
- Davon die achte Spalte
$ ping -c 1 www.schauderbasis.de | sed -n 2p | awk '{print $8}'
time=29.1
- Und dann alles ab dem sechsten Buchstaben:
$ ping -c 1 www.schauderbasis.de | sed -n 2p | awk '{print $8}' | cut -c 6-
29.6
Wunderbar.
Mehr Werte
Damit wir nachher eine ordentliche Datenbasis haben, wollen wir viele
Werte hintereinander generieren. Eigentlich macht das ping ja
schon selbst, aber wir bauen uns hier eine eigene Schleife, so das wir Daten sofort einlesen können.
Optionale Argumente (wusste ich vorher auch nicht) gehen so:
# number of datapoints to generate: take first argument or 10 as default
n=${1:-10}
# sleeptime: take second argument or 1 as default
t=${2:-1}
Am Ende (mit ein bisschen Zeug aus dem nächsten Abschnitt) sieht das ganze so aus.
database_name="pingDB"
table_name="pingtimes"
url="www.schauderbasis.de"
dbdo="mysql -u root -s $database_name -e"
# number of datapoints to generate: take first argument or 10 as
# default
n=${1:-10}
# sleeptime; take second argument or 1 as default
t=${2:-1}
for i in `seq $n`
do
pingtime=$(ping -c 1 $url | sed -n 2p | awk '{print $8}' | cut -c 6-)
$dbdo "insert into $table_name (Zeitpunkt, URL, Ping) values (NOW(), '$url', $pingtime);"
sleep $t
done
Gar nicht mal so hässlich, von bash bin ich schlimmeres gewohnt.
Die Datenbank - MariaDB
Es gibt verschiedene Datenbanken für verschiedene Zwecke. Ich habe mich für MariaDB entschieden, hauptsächlich wegen dem Artikel im Arch-Wiki zum aufsetzen und dem Tutorial auf der Website von MariaDB, das mit genau so viel Information gegeben hat wie ich als blutiger Anfänger brauchte.
Beim Lernen hat mir wirklich sehr geholfen, das ich mit einem Makefile arbeite. So konnte ich einfach Zeilen wie diese eintragen:
database_name = pingDB
table_name = pingtimes
general_do = mysql -u root -e
dbdo = mysql -u root $(database_name) -e
prepare_database:
$(general_do) "create database if not exists $(database_name)"
prepare_table:
$(dbdo) "create table if not exists $(table_name) (Zeitpunkt TIMESTAMP, URL VARCHAR(30), Ping FLOAT UNSIGNED)";
show_table:
$(dbdo) "select * from $(table_name)"
Was man sich aufgeschrieben hat, kann man schon mal nicht wieder vergessen.
Tatsächlich ist die SQL-Syntax gar nicht so schlimm, solange man relativ einfache Anfragen stellt. Das war bei mir zum Glück der Fall und das bisschen was ich brauchte konnte ich dann auch relativ flott auswendig.
Am Ende hatte ich eine Datenbank mit einer Tabelle, die (mit dem Skript von oben) so aussah:
$ make show_table
mysql -u root pingDB -e "select * from pingtimes"
+---------------------+----------------------+------+
| Zeitpunkt | URL | Ping |
+---------------------+----------------------+------+
| 2016-01-25 16:56:40 | www.schauderbasis.de | 29.8 |
| 2016-01-25 16:56:41 | www.schauderbasis.de | 30.1 |
| 2016-01-25 16:56:42 | www.schauderbasis.de | 29.0 |
| 2016-01-25 16:56:43 | www.schauderbasis.de | 32.2 |
| 2016-01-25 16:56:44 | www.schauderbasis.de | 28.8 |
| 2016-01-25 16:56:45 | www.schauderbasis.de | 29.6 |
| 2016-01-25 16:56:47 | www.schauderbasis.de | 30.1 |
| 2016-01-25 16:56:48 | www.schauderbasis.de | 29.8 |
| 2016-01-25 16:56:49 | www.schauderbasis.de | 28.6 |
| 2016-01-25 16:56:50 | www.schauderbasis.de | 29.2 |
+---------------------+----------------------+------+
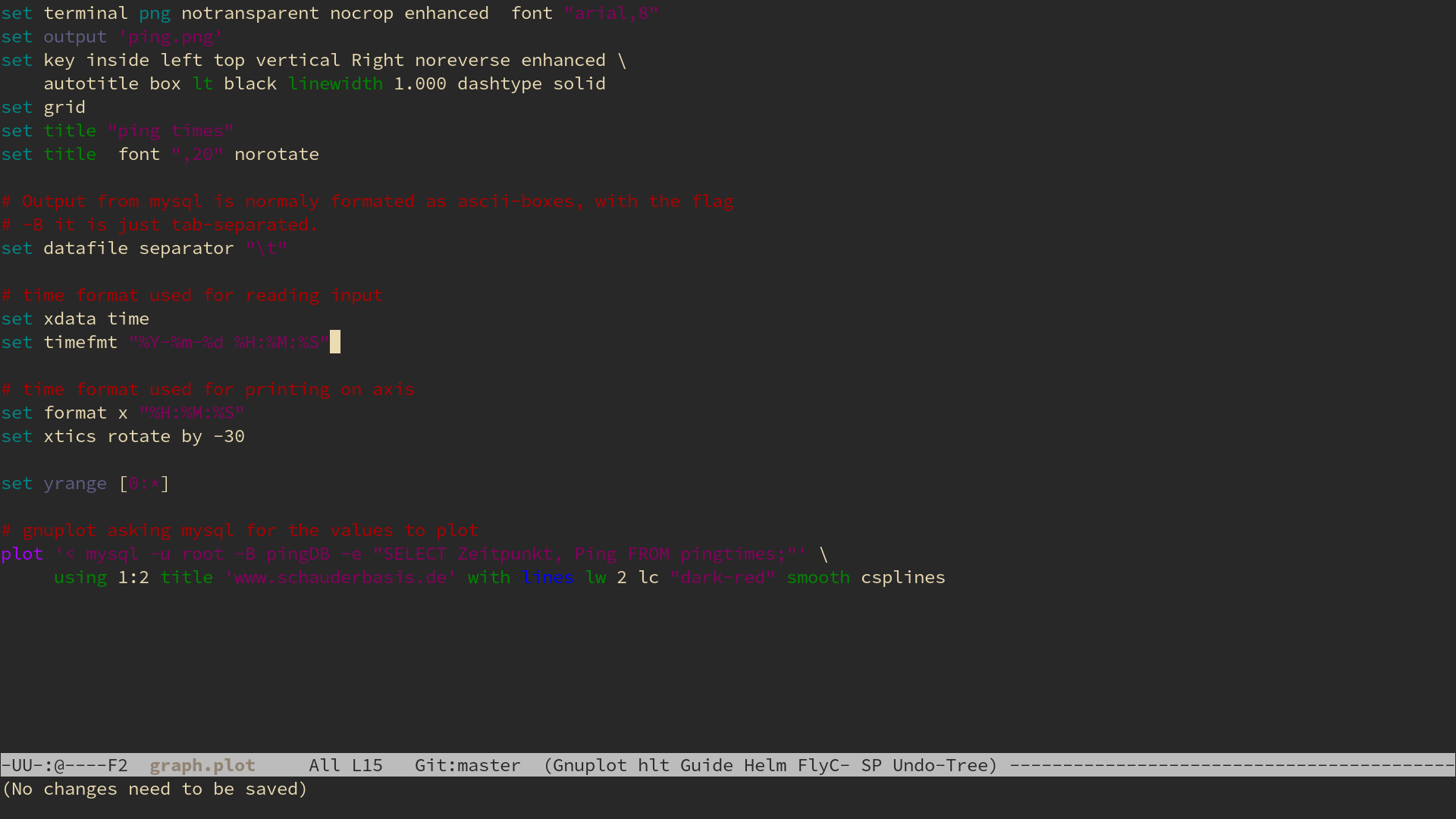
Die Datenaufbereitung - Gnuplot
Eigentlich kam für mich kein anderes Tool in Frage, Gnuplot passt einfach zu gut. Ich habe schonmal was zu verschiedenen Plottern aufgeschrieben und hier war die Entscheidung klar.
Das schwierigste war die Frage, wie man die Daten aus der Datenbank in Gnuplot hinein bekommt. Gut das Gnuplot alles kann:
# Output from mysql is normaly formated as ascii-boxes,
# with the flag -B it is just tab-separated.
set datafile separator "\t"
plot '< mysql -u root -B pingDB -e "SELECT Zeitpunkt, Ping FROM pingtimes;"' using 1:2
Im Prinzip wird hier die SQL-Abfrage direkt von Gnuplot ausgeführt. Kein Problem.
Es ist gar nicht so klar, wie das mit der Zeit eingelesen werden soll. SQL liefert das Datum und die Uhrzeit schön nach ISO 8601: 2016-01-25 16:56:40
Gnuplot kommt von klugen Leuten, die wissen dass es auf der Welt sehr viele sehr schlimme Formate gibt, in der Leute die Zeit angeben. Deswegen gibt man einfach an, in welchem Format das Datum eingelesen und ausgegeben werden soll:
# time format used for reading input
set xdata time
set timefmt "%Y-%m-%d %H:%M:%S"
# time format used for printing on axis
set format x "%H:%M:%S"
Einfacher geht es nicht. Eine Aufschlüsselung der Variablen (falls nötig) gibt es im hervorragenden Handbuch. Es scheint aber das gleiche Format zu sein wie bei dem Programm date, also reicht wsl auch die entsprechende manpage.
Jetzt ist nur noch die Frage, wie der Graph aussehen soll. Ich habe mich entschieden, die Werte interpolieren zu lassen, damit der Graph schön glatt ist. Das Stichwort hier heißt smooth, man sollte es in Gedanken aber immer smooooooooth aussprechen.
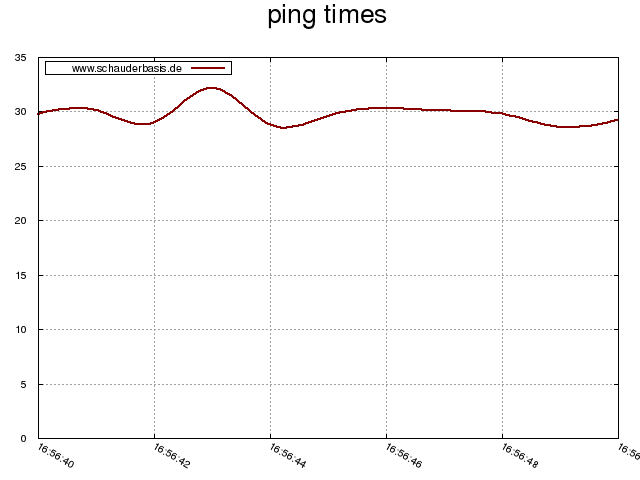
Und das wars
Eigentlich ziemlich einfach, hier funktionieren ein paar mächtige Werkzeuge sehr gut zusammen. Es hat Spaß gemacht und ich habe jede Menge über wichtige Standardwerkzeuge gelernt.
Der Code liegt hier zur freien Verfügung (mit freier Lizenz natürlich).
Gedanken zum Projekt
- Für so ein kleines Projekt würde man normalerweise keine riesige Datenbank anschmeißen. Matthias meinte, dass die meisten Leute die nicht wissen welche Datenbank sie benutzen sollen mit sqlight wahrscheinlich am besten bedient sind.
- Bash ist eine furchtbare Programmiersprache. Aber leider sehr nützlich.
- Ich weiß nicht wer sich ausgedacht hat, dass Variablen in Make und bash fast, aber nur fast gleich aussehen und funktionieren. Was soll das?
- Ich war erst ein bisschen genervt, dass man in SQL immer brüllen muss: “CREATE TABLE IF NOT EXISTS pingtimes”. Dann habe ich gemerkt, dass das gar nicht notwendig ist - die Sprache ist case insensitive: “create table if not exists pingtimes”. Manche Sachen (zum Beispiel die Datentypen) habe ich trotzdem in Caps gelassen, das sah irgendwie richtiger aus.
- Wenn ich cooler wäre würde ich einen Cronjob einrichten, der das Skript regelmäßig anstößt (~alle 5 Minuten?). Das könnten interessante Graphen sein.
- Mit wenig Aufwand könnte man das Skript umbauen, so dass andere
Werte aufgezeichnet und verarbeitet werden. Zum Beispiel:
- die Batterie (Wie viel Prozent habe ich im Schnitt noch übrig?)
- RAM und CPU
- Wie viele Wlans verfügbar sind (verschlüsselt vs. unverschlüsselt?)
- Nachdem ich viel im Internet nach Gnuplotschnipseln gestöbert habe entdeckte ich gegen Ende des Projektes, dass Gnuplot ein hervorragendes und ausführliches Handbuch mit vielen Beispielen und Bildern hat. Nächstes mal weiß ich das vorher.